About this Document
Background
This
document will cover ADOP patching concept with cutover in detail consideration.
Intended Audience
This
document is primarily meant for database administrators, system administrators,
Team Leaders, Technical Managers, etc.
References
ADOP Cutover
Fails, Timeout While Starting Services On Secondary Node (Doc ID 2411800.1)
R12.2 ADOP
Phase=cutover Fails Timed Out In Adnodemgrctl.sh (Doc ID 1640587.1)
Google
Pythian Blogs
Currently customer is using Oracle EBS r12.2.x.
Online patching
allows better prediction of downtime and has significantly reduced downtime
compared to r12.1.x. EBS r12.2 stores multiple editions of application code
(using Edition based redefinition feature). The complete cycle takes
considerably more time than before, however, cutover phase has been kept to a
minimum to reduce downtime.
ADOP cycle
consists of difference phases and each phase needs to be thoroughly understood
before applying patches using adop.
1.
Prepare –
Creates a virtual copy (patch edition) of Run Edition
FscloneStage and FscloneApply is used to copy files
from run edition to patch edition (synchronizes files but not configurations)
Validations and checks are done after copy
2.
Apply –
Applies patches on the Patch edition of dual
filesystem
Need to make sure hotpatch is ‘hotpatch’ applicable,
else system may hang when using hotpatch mode.
3.
Finalize-
Prepares system for cutover phase.
Compilation of objects
4.
Cutover –
Perform a cutover to Patch Edition and make it run
Edition
It’s the most sensitive phase. Users cannot connect to
the system during cutover phase.
5.
Cleanup –
Will remove obsolete definitions
6.
Abort –
Using this option, we can return to normal runtime
operation if a patch cycle has failed.
Abort can be used if system is in below phases
-
Prepare
-
Finalize
-
Cutover
Once cutover completes, we cannot run abort.
CUTOVER
phase fails or terminates in the middle. Please describe how would you solve /
workaround the problem and complete the switchover.
Cutover phase may fail for different stages like as
follows –
1.
Shutting down ICM and apps tier services and
acquiring lock on AD_ADOP_SESSIONS
2.
Database level cutover
3.
Switchover of filesystem from run edition to
patch edition
4.
Starting up admin server
We need to investigate and find out in which stage
cutover has failed, this can be done using below query –
set pagesize 200;
set linesize 160;
col PREPARE_STATUS format a15
col APPLY_STATUS format a15
col CUTOVER_STATUS format a15
col ABORT_STATUS format a15
col STATUS format a15
select NODE_NAME,ADOP_SESSION_ID, PREPARE_STATUS , APPLY_STATUS
,CUTOVER_STATUS , CLEANUP_STATUS , ABORT_STATUS , STATUS
from AD_ADOP_SESSIONS
order by ADOP_SESSION_ID;
Understanding status codes of cutover –
cutover_status='Y' 'COMPLETED'
cutover_status not in ('N','Y','X') and status='F'
'FAILED'
cutover_status='0' 'CUTOVER STARTED'
cutover_status='1' 'SERVICES SHUTDOWN COMPLETED'
cutover_status='3' 'DB CUTOVER COMPLETED'
cutover_status='D' 'FLIP SNAPSHOTS COMPLETED'
cutover_status='4' 'FS CUTOVER COMPLETED'
cutover_status='5' 'ADMIN STARTUP COMPLETED'
cutover_status='6' 'SERVICES STARTUP COMPLETED'
cutover_status='N' 'NOT STARTED'
cutover_status='X' 'NOT APPLICABLE'
CUTOVER_STATUS column will show either Y for
completion status or any of above status codes and accordingly we will
understand exactly which stage, cutover has failed.
Each stage will require a different action plan and
decision making, let’s start with exploring each stage-
Scenario 1 -
1. Shutting down ICM and apps tier services
acquiring lock on AD_ADOP_SESSIONS
You can manually check and make sure if all
application services are down.
ps -ef | grep applmgr
2.
Sometimes a terminated adop session can also
create issues to current adop cycle.
Check below output for select query to find problematic session in
AD_ADOP_SESSIONS table
select * from ad_adop_sessions where
edition_name='LOCK' ;
Unlock session using below command manually to check if error exists
again-
begin
AD_ZD_ADOP.UNLOCK_SESSIONS_TABLE('<hostname>',60,2);
end;
/
UNLOCK_SESSIONS_TABLE procedure takes below arguments
-----------------
P_NODE_NAME
P_WAIT_INTERVAL
P_NUM_TRIES
It is always recommended to have further diagnostics done to find root
cause of terminated session, Oracle has provided generic patch
p19045166_R12_GENERIC for 12.2 customers to collect these diagnostics.
3.
Monitor long running concurrent programs using
below queries –
SELECT DISTINCT c.USER_CONCURRENT_PROGRAM_NAME,
round(((sysdate-a.actual_start_date)*24*60*60/60),2) AS Process_time,
a.request_id,a.parent_request_id,a.request_date,a.actual_start_date,a.actual_completion_date,
(a.actual_completion_date-a.request_date)*24*60*60 AS end_to_end,
(a.actual_start_date-a.request_date)*24*60*60 AS lag_time,
d.user_name,
a.phase_code,a.status_code,a.argument_text,a.priority
FROM
apps.fnd_concurrent_requests a,
apps.fnd_concurrent_programs b ,
apps.FND_CONCURRENT_PROGRAMS_TL c,
apps.fnd_user d
WHERE
a.concurrent_program_id=b.concurrent_program_id AND
b.concurrent_program_id=c.concurrent_program_id AND
a.requested_by=d.user_id AND
status_code='R' order
by Process_time desc;
Scenario 2 -
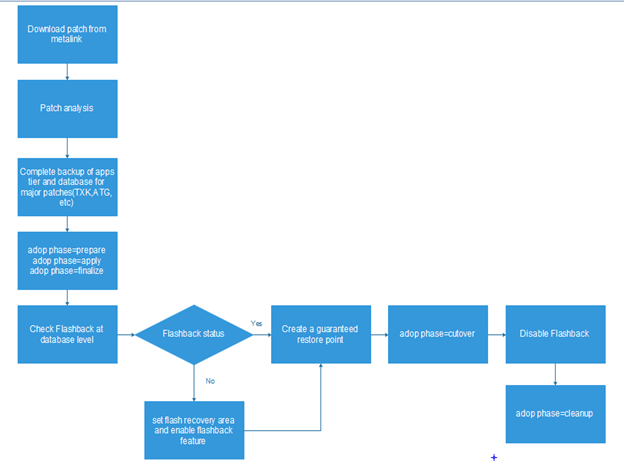
Database level cutover
It is always recommended to take complete backup of system before
applying any patch that should include,
- Database backup
- Apps tier backup
However, this may not be suitable for applying smaller patches and
therefore, we should use Flashback technology for creating snapshots/before
images of database. This simplifies rolling back patch after database editions
have been updated.
Flashback uses db_recovery_file_dest location to store flashback logs.
They are retained as per retention policy and automatically cleared. However,
if we have set a guaranteed restore point, they are retained until we dropped
restore point.
A restore point can be created just before starting cutover phase at db
level to make sure we can fix failed cutover phase.
Steps to create restore point –
a.
Check flashback is enabled for the database –
SQL> select name,open_mode, FLASHBACK_ON from
v$database;
NAME
OPEN_MODE FLASHBACK_ON
--------- -------------------- ------------------
OAMREPO READ
WRITE NO
b.
Set db_recovery_file_dest_size first and then
db_recovery_file_dest
SQL> alter system set
db_recovery_file_dest_size=20g;
System altered.
SQL> alter system set
db_recovery_file_dest='/u01/app/oracle/db/12.1.0/fra';
System altered.
SQL>
c.
Enable Flashback as follows –
SQL> alter database flashback on;
Database altered.
SQL> show parameter db_flashback
NAME TYPE VALUE
------------------------------------ -----------
------------------------
db_flashback_retention_target integer 1440
SQL> alter system set
db_flashback_retention_target=120;
System altered.
d.
Creating guaranteed restore point
We will follow normal patching cycle until cutover phase as follows
adop phase=prepare
adop phase=apply
adop phase=finalize
Once finalize phase completes, just before starting cutover phase, we
will create a guaranteed restore point as follows –
SQL> alter system switch logfile;
System altered.
SQL> create restore point before_change_pwd
guarantee flashback database;
Restore point created.
SQL> alter system switch logfile;
System altered.
SQL>
e.
Cutover phase
Execute adop phase=cutover and monitor log for any
errors
Suppose cutover phase fails in this case, we have a
guaranteed restore point to flashback database to ‘before_patch_19045166’
f.
Rolling back to state before cutover
This can be achieved at database level following steps –
a. Shutdown database
SQL> shut immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
b. Start database in mount state
SQL> startup mount;
ORACLE instance started.
Total System Global Area 809500672 bytes
Fixed Size
2929600 bytes
Variable Size 394267712 bytes
Database Buffers 406847488 bytes
Redo Buffers 5455872 bytes
Database mounted.
c. Flashback database to restore point
before_patch_19045166
SQL> flashback database to restore point
before_patch_19045166;
Flashback complete.
d. Startup database in mount and open with
resetlogs option
SQL> alter database open resetlogs;
Database altered.
SQL>
e. Drop guaranteed restore point
SQL> drop restore point before_patch_19045166;
Restore point dropped.
SQL>
f.
Disable flashback until next patching cutover phase
SQL> alter database flashback off;
Database altered.
SQL> alter system set db_recovery_file_dest='';
System altered.
Scenario 3 -
Switchover of filesystem from run edition to
patch edition. This can be observed in cutover logfile under location –
$NE_BASE/EBSApps/log/adop/session_id/cutover_timestamp/
If
adop fails during cutover phase, there are 2 possibilities,
a.
Filesystems are not switched
-
Perform steps in scenario 2
to rollback changes done by patch.
-
No action required as run
edition is not updated by the patch.
-
Shutdown all services and
start apps tier as normal procedure.
-
Now system is back in
finalize phase and you can decide to abort online patching cycle.
b.
Filesystems are
switched (Patch edition is now new run edition, and old run edition is now
patch edition)
-
Source run file system environment
-
Shutdown apps tier
(adstpall.sh)
-
Perform a switch back($FND_TOP/bin/txkADOPCutOverPhaseCtrlScript.pl)
$ perl
$AD_TOP/patch/115/bin/txkADOPCutOverPhaseCtrlScript.pl
-action=ctxupdate
-contextfile= <full path of new run filesystem>
-patchcontextfile= <full path of new patch filesystem>
-outdir=
<out directory path)
-
Startup all services from
new run file system
Scenario 4-
Starting up admin server
Below references have been observed
specifically to cutover failing due to start up issues of admin server.
-
Adop Cutover Failed by
"[UNEXPECTED]Error occurred starting Admin Server" on Run File System
(Doc ID 2314018.1)
-
ADOP Cutover Fails, Timeout
While Starting Services On Secondary Node (Doc ID 2411800.1)
Ideal approach in this is to use complete
cutover phase by skipping middle tier restart –
adop phase=cutover mtrestart=no
Once cutover completes, manually start services
and further troubleshoot.
Scenario 5-
Wrong configuration in single/multimode setup. Oracle has further
provided some notes on cutover failing due to wrong configuration in both
single/mutlnode setup.
a.
Wrong options used to mount NFS share where apps
tier is deployed
b.
CONTEXT_FILE parameters wrongly set ( like s_appltmp, s_batch_status, s_apctimeout)
c. Supporting Metalink Notes -
- 12.2 ADOP Cutover Fails With forceStartupServices (Doc ID 1573972.1)
- 12.2
E-Business Suite ADOP Cutover, Abort, or Fs_clone Fails With 'ERROR: The value
of s_appltmp is not correct in run edition context file' As s_appltmp Has Been
Customized To A Shared Location On All Nodes (Doc ID 2220669.1)
- Cutover
Phase failed due to wrong configuration of services (Doc ID 2384839.1)
Conclusion
–
1. It is recommended to perform patch
analysis before applying any patch to ebs environment
2. If we are applying patches for major
release upgrades, then we must take a complete backup of apps tier and
database.
3. Enable flashback at database level and
create a guaranteed restore point before cutover.
4. Always review logs under below location
and try to find solution first before performing switch back
$NE_BASE/EBSApps/log/adop/session_id/cutover_timestamp/
5. We must review metalink notes and
implications of action plan with respect to environment
6. We can always raise Severity 1 SR for
patch failures and get solution.